FAQpage 構造化データをJavaScriptで自動生成するコード [JSON-LD]
Googleの検索結果をおしゃれにする構造化データという仕組みがありますが、FAQ形式の構造を生成する際に悩んだので解決策の一例を説明します。
やりたいこと
- Googleのリッチリザルト検索結果にてこんなUIを表現したい
- 情報源となるコンテンツは、記事そのものに違和感なく溶け込ませたい
このように
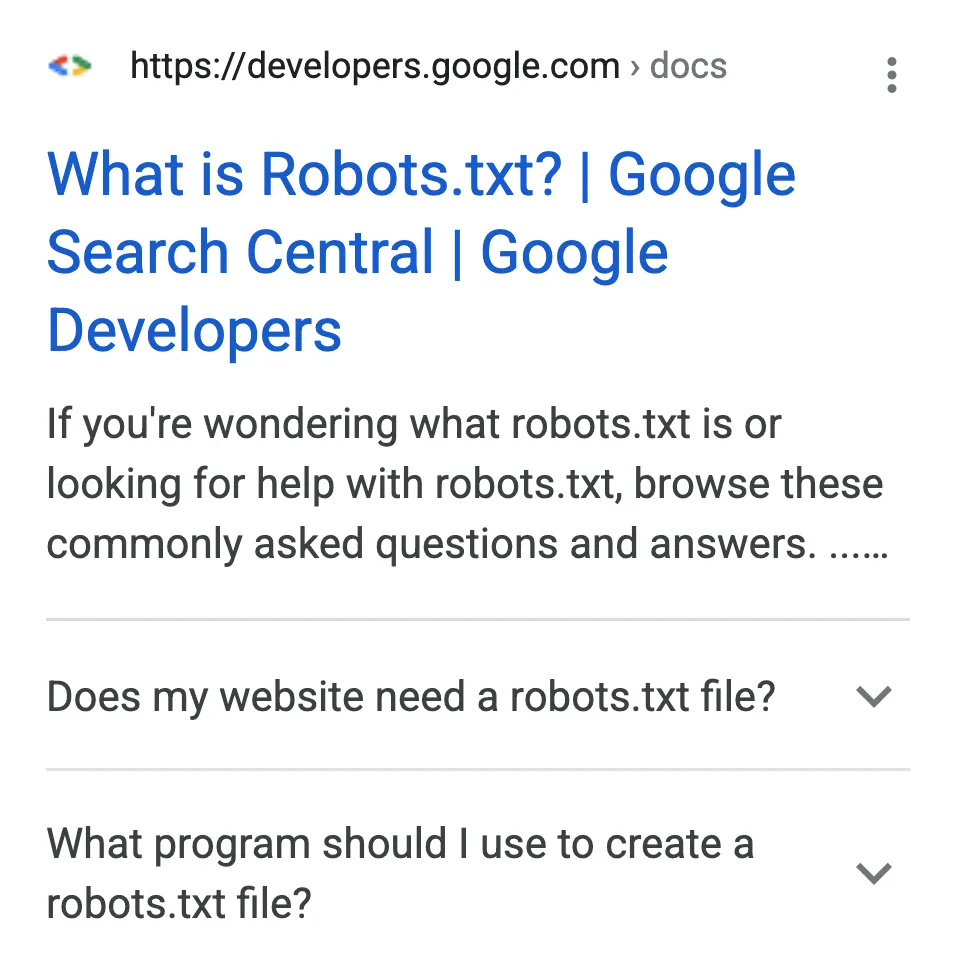
引用 検索ギャラリーとリッチリザルトを見る | 検索セントラル | Google Developers
解決策と解決策のコード
記事の中にある質問部分、および回答部分それぞれを JavaScript で抽出して、さらに JSON-LD 形式の <script> タグを JavaScript で動的に生成することにしました。
// HTML ドキュメントの読み込みを待つトリガー
window.addEventListener("DOMContentLoaded", () => {
// JSON-LD 形式の Schema を生成する処理の開始
createFaqSchema();
});
function createFaqSchema() {
// 質問情報のあるセクションを抽出
let questions = document.querySelectorAll(".question-section");
if (!questions.length) {
// 質問に関するコンテンツがなかった場合は処理を終了
return false;
}
// 質問と回答のセットを格納するための変数。つまりセットはいくつあってもよい。
const entities = [];
questions.forEach((section) => {
// 質問そのものの抽出
let question = section.querySelector(".question").innerText;
// 回答そのものの抽出
let answer = section.querySelector(".answer").innerHTML.trim();
entities.push(createQuestionEntity(question, answer));
});
const schemaBody = {
"@context": "https://schema.org",
"@type": "FAQPage",
mainEntity: entities,
};
createSchemaElement(JSON.stringify(schemaBody));
}
// <head> タグ内に <script> タグを生成する
function createSchemaElement(structuredDataText) {
const script = document.createElement("script");
script.setAttribute("type", "application/ld+json");
script.textContent = structuredDataText;
document.head.appendChild(script);
}
function createQuestionEntity(question, answer) {
if (!question) {
return false;
}
if (!answer) {
return false;
}
return {
"@type": "Question",
name: `${question}`,
acceptedAnswer: {
"@type": "Answer",
text: `${answer}`,
},
};
}
この JavaScript で FAQ 形式のデータを抽出するには、以下の形式のHTMLがあることを期待します。
<div class="question-section">
<span class="question">インターネットとはなんですか?</span>
<div class="answer">
インターネットは、世界中のコンピュータなどの情報機器を接続するネットワークです。
</div>
</div>
以降、詳細を解説します。
構造化データとは
Google の検索結果はテキストに限らず、画像があったり横にスクロール(スワイプ)できたり、リッチなUIを度々見かけます。
これらは構造化データと呼ばれるマークアップ(コーディング)をすることで実現できます。
例えば、以下のようなコードを記載することで図に示すような見た目が表現できます。<script> ~ </script> の部分がポイントです。
<html>
<head>
<title>Party Coffee Cake</title>
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Recipe",
"name": "Party Coffee Cake",
"author": {
"@type": "Person",
"name": "Mary Stone"
},
"datePublished": "2018-03-10",
"description": "This coffee cake is awesome and perfect for parties.",
"prepTime": "PT20M"
}
</script>
</head>
<body>
<h2>Party coffee cake recipe</h2>
<p>
<i>by Mary Stone, 2018-03-10</i>
</p>
<p>
This coffee cake is awesome and perfect for parties.
</p>
<p>
Preparation time: 20 minutes
</p>
</body>
</html>
- “構造化データの仕組みについて | Google 検索セントラル | Google Developers”
- https://developers.google.com/search/docs/advanced/structured-data/intro-structured-data?hl=ja
この記事では FAQpage 形式を対象に解説していますが、ほかにもこのように多数のリッチリザルトの種類があるので眺めてみるのも楽しいです。
- 検索ギャラリーとリッチリザルトを見る | 検索セントラル | Google Developers
- https://developers.google.com/search/docs/advanced/structured-data/search-gallery?hl=ja
構造化の表現方法
リッチな結果を表示するためには、Googleなどの検索エンジンに対してどこにどういう情報があるのかを示してあげる必要があります。この行為をマークアップと表現されています。
理想的には、Googleなど検索エンジンのBot(巡回ロボット)が対象サイトの情報を正確に理解して勝手に意味をつけてくれるのが理想ですよね。ですが、無数に存在しているWebサイトそれぞれの意味を正確に理解するのは現在の技術ではまだ困難そうです。
そのためWebサイトの持ち主が、自分のサイトがどういうものなのかをロボットのために補足説明してあげるわけですね。
- このページは料理のレシピを掲載しているよ!
- この料理のカロリーはいくつあるよ!
- この料理時間の目安は何分だよ!
このようなことを教えてあげるわけです。
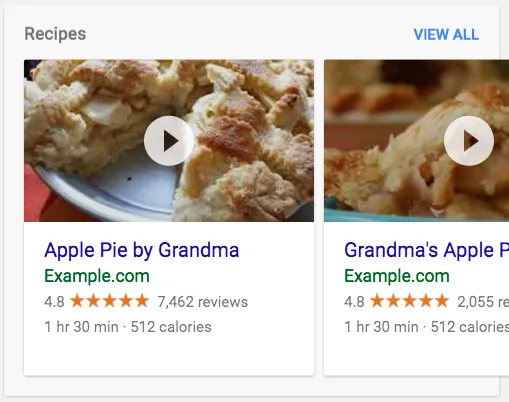
引用 検索ギャラリーとリッチリザルトを見る | 検索セントラル | Google Developers
マークアップの表現方法には以下の種類があります。
| 形式 | 仕様リンク |
|---|---|
| JSON-LD(Googleも推奨) | https://json-ld.org/ |
| microdata | https://html.spec.whatwg.org/multipage/microdata.html#microdata |
| PDFa | https://www.w3.org/TR/rdfa-lite/ |
よほど困る理由がなければ JSON-LD 形式がお手軽で良いと思います。
microdata 形式は HTML タグに対して直接意味を付与していくので、ページのデザイン変更などで構成が変わったら追従が面倒くさいからです。なお PDFa 形式は利用したことがないのですが、microdata っぽい使い勝手に見えますね。
microdata形式
itemprop="xxx" のようなプロパティ指定をたくさん書く必要があります。
<div itemscope>
<p>My <em>name</em> is <span itemprop="name">E<strong>liz</strong>abeth</span>.</p>
</div>
<section>
<div itemscope>
<aside>
<p>My name is <span itemprop="name"><a href="/?user=daniel">Daniel</a></span>.</p>
</aside>
</div>
</section>
PDFa形式
<p vocab="http://schema.org/" typeof="Person">
My name is
<span property="name">Manu Sporny</span>
and you can give me a ring via
<span property="telephone">1-800-555-0199</span>
or visit
<a property="url" href="http://manu.sporny.org/">my homepage</a>.
</p>
構造化の課題
FAQコンテンツをページのどこに配置するかという問題です。
今回やりたかったのは、ページ内のどこにあるか分からないFAQの情報をいい感じに抽出したいということでした。
WordPressのような利用者数が多い定番システムであれば解決策も多数あるでしょうが、独自システムを含めマイナーな方式を採用している場合はなかなか難しい問題です。いい解決策はないものかとドキュメントを読んでいたところ、 JavaScript を仕様して構造化データを作れることに気づきました。
- JavaScript を使用して構造化データを生成する | Google 検索セントラル | Google Developers
- https://developers.google.com/search/docs/advanced/structured-data/generate-structured-data-with-javascript?hl=ja
Chrome のデバッガで実装を確認してみると HTML 要素がうまく表示できていたので、最後に Google のリッチリザルトテストで実行結果を試します。
- リッチリザルト テスト - Google Search Console
- https://search.google.com/test/rich-results
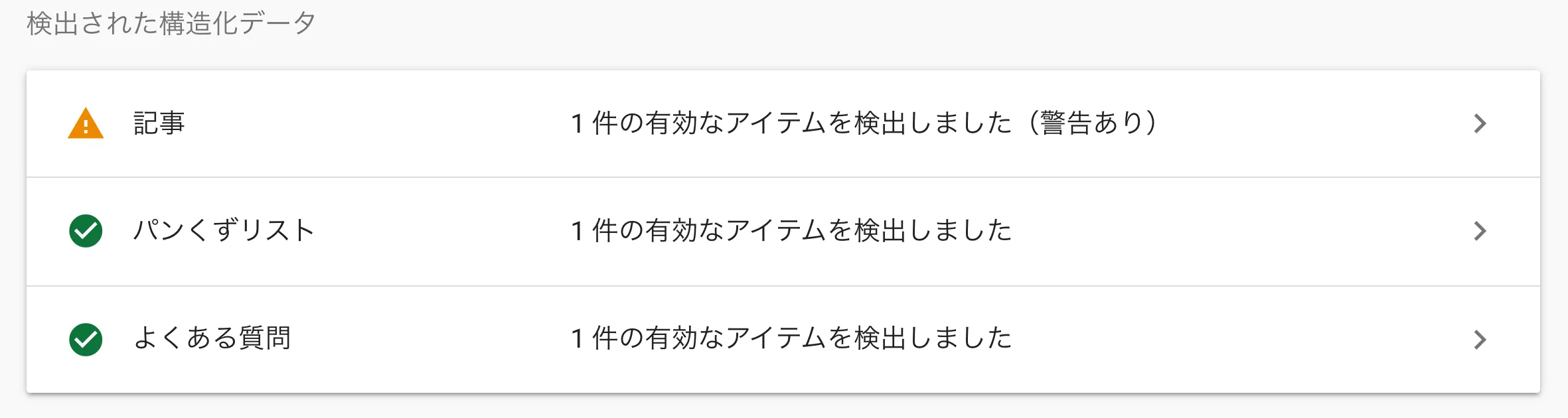
「よくある質問」として構造化データが認識されたようです。(注 「記事」で警告マークが出ていますが別の理由によるものなので無視してください)
まとめ
構造化データを JavaScript で動的に生成し、それを Google の構造化データ認識テスト(リッチリザルトテスト)にかけたところ期待通りの動作をしてくれました。
この手法は純粋な JavaScript と HTML のみで実現していますので、Webサイトを生成するシステムに依存しないところがメリットになりそうです。
解決策の一例としてご確認ください(なおテストしたばかりのため、実際に結果が反映されるところまではテストしていません)