GCP の Kubernetes サービス (GKE) にて格安ノード Preemptible VM を利用してクラスタを構築しているのですが、Preempbile VM は性質上、24時間で強制終了されてしまいます。その対策に Preemptible VM Killer をセットアップしようとしたところ、 GCPのIAM関連機能である Workload Identity について試す機会が得られたため、機能や使い方を整理しました。
Workload Identity だけで文章量が増えてしまったため、本題の Preemptible VM Killer については別の記事で記載します。
Preemptible VM Killer: estafette/estafette-gke-preemptible-killer: Kubernetes controller to spread preemption for preemtible VMs in GKE to avoid mass deletion after 24 hours
Workload Identity の具体的利用例として以下の記事も参考にしてみてください。何のキーに対してどのような操作をするのかが一通り把握できると思います。

要約
- Workload Identity を利用すると、Google Cloud Platform の世界のサービスアカウント (
GAS_NAME@PROJECT_ID.iam.gserviceaccount.com形式) と Kubernetes の世界のサービスアカウント (kubectl create serviceaccount ...形式) をマッピングすることができる- 結果、Kubernets の ServiceAccount が、GCP 上の ServiceAccount と同じ権限で振る舞うことができる
- AWS (EKS) の知見がある場合は、
eksctlコマンドや ConfigMap のaws-authで設定する内容と同等の性質と捉えられる。 Enabling IAM user and role access to your cluster - Amazon EKS
- Workload Identity を利用しなくても、シークレットキーあるいは Kubernetes ワーカーノードの権限でも機能上は同等のことができるが、Google Cloud では Workload Identity の利用が強く推奨されている。
- 大きな手順は以下の通りで、GKEに向けた特殊性は最後のマッピング設定くらいなのでシンプル
- (前提) GKEクラスタの Workload Identity が有効になっていること。無効の場合は有効にする作業をする
- GCPのサービスアカウント、および必要な権限を設定したRoleや関連付け(Binding)をしておく
- Kubernets 内にサービスアカウントを作成する。(既にある場合は省略)
- 最後に、Kubernetes サービスアカウントと GCPサービスアカウントをマッピングする。具体的には以下の通り2つの作業をする。
- GCPのプロジェクト内での関連付け操作
- Kubernets サービスアカウントの annotation にて、関連付け対象の GCP サービスアカウントを定義する操作
コマンド例
コマンド例(GCPサービスアカウントと Kubernetes サービスアカウントの関連付け操作):
gcloud iam service-accounts add-iam-policy-binding $GSA_NAME@$GSA_PROJECT.iam.gserviceaccount.com \
--role roles/iam.workloadIdentityUser \
--member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]"roles/iam.workloadIdentityUser の意味は後述しています。
コマンド例(Annotation の付け方):
# Kubernetes のサービスアカウントに annnotation で GCP サービスアカウントを付与する
# 値は GCP サービスアカウントのメールアドレス形式となる
kubectl annotate serviceaccount $KSA_NAME \
--namespace $NAMESPACE \
iam.gke.io/gcp-service-account=${GSA_NAME}@${GSA_PROJECT}.iam.gserviceaccount.comWorkload Identity の利用が強く推奨されている
以下の記載からも、意識的に使うか使わないかはおいといてサービスアカウントキーを利用しないアーキテクチャが主流なことを踏まえ、Workload Identity そのものは有効化してくほうが長い目では良いと思います。

サービス アカウントを使用した Google Cloud への認証 | Kubernetes Engine
Workload Identity を使用するための理解
このセクション以降は、理解を深めるための具体的な情報整理や作業手順を記載します。
なぜ Workload Identity が必要なのか
パブリッククラウドインフラストラクチャ(AWSやGCP等)を利用したアプリケーション設計では外部リソースへアクセスするための権限管理としてロールを利用する、言い換えると クレデンシャルキーなどの秘匿情報を個別に管理しない手段が推奨されています。
GKE では例えば、実行されるアプリケーションでが Compute Engine API、BigQuery Storage API、Machine Learning API などの Google Cloud APIs へのアクセスが必要になるケースもあるでしょう。そういうケースで Workload Identity は、GKE クラスタ内の Kubernetes サービス アカウントが IAM サービス アカウントとして自動的に認証されて機能できるようになります。よって、Workload Identity を使用すると、クラスタ内のアプリケーションごとにきめ細やかに設定した個別の ID および 認可を割り当てることができるようになります。
Workload Identity の基礎知識
- クラスタで Workload Identity を有効にすると、GKE によって次の形式でクラスタの Google Cloud プロジェクトに固定の Workload Identity プールが自動的に作成される。
PROJECT_ID.svc.id.goog
- Workload Identity プールには、IAM が Kubernetes サービス アカウントの認証情報を把握して信頼できるようにする命名形式が用意されている。
- Workload Identity を有効にしても、デフォルトではワークロードに IAM 権限は付与されない。
- 名前空間 (Namespace) で Kubernetes サービス アカウントを構成して Workload Identity を使用する場合、IAM は次のメンバー名に基づいて認証する。
serviceAccount:PROJECT_ID.svc.id.goog[KUBERNETES_NAMESPACE/KUBERNETES_SERVICE_ACCOUNT]
- Workload Identity が有効になっている GKE のすべてのノードは、そのメタデータを GKE メタデータ サーバーに保存する。
- GKE メタデータ サーバーは、Kubernetes ワークロードに必要な Compute Engine メタデータ サーバー エンドポイントのサブセットのこと。
- GKE メタデータ サーバーは DaemonSet として実行される。それぞれの Linux ノードで 1 つの Pod が使用される(Windows ノードの場合には、ネイティブ Windows サービスが実行される)。
- メタデータ サーバーは、
http://metadata.google.internal(169.254.169.254:80)への HTTP リクエストをインターセプトします。たとえば、GET /computeMetadata/v1/instance/service-accounts/default/tokenのような形式。
Worklowad Identity の有効化
保有している GKE クラスタの Workload Identity の設定状況によって事前準備が少々異なります。
クラスタの設定変更
GKE クラスタの新規作成時はもちろん、Workload Identity が無効の既存クラスタがある場合でも以下の通りアップデートが可能です。
# 変数の準備。環境に合わせて記載すること
CLUSTER_NAME=change
COMPUTE_REGION=change
PROJECT_ID=change
# 新規クラスタで作成する場合
gcloud container clusters create $CLUSTER_NAME \
--region=$COMPUTE_REGION \
--workload-pool=${PROJECT_ID}.svc.id.goog
# 既存クラスタで更新する場合
gcloud container clusters update $CLUSTER_NAME \
--region=$COMPUTE_REGION \
--workload-pool=${PROJECT_ID}.svc.id.goog設定変更の完了は、Web コンソールからも確認することができます。
-
Workload Identity が 「有効」になっている
-
Workload Identity の名前空間に 「PROJECT_ID.csv.id.goog」の値が表示されている(適用前は存在しない項目)

ノードプールの変更
Workload Identity が「無効」の既存クラスタを有している場合の作業です。クラスタで Workload Identity を有効にした後、既存のノードプールで手動で有効にできます。内容的には設定変更ではなくノードの再構築になりますね(Node Pool により自動で進めてくれます)
# 変数の準備。環境に合わせて記載すること
NODEPOOL_NAME=change
CLUSTER_NAME=change#前の手順で設定済み
gcloud container node-pools update $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--workload-metadata=GKE_METADATA一通りの Pool を再構築した結果、以下の新しいPodが作成されました。
gke-metadata-server は想定通りですが、 netd というPodも登場していますね。GCPのネットワーク関連機能を提供する Daemonset のようです。
GoogleCloudPlatform/netd: netd: GKE Networking Daemonset
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system gke-metadata-server-cqv6d 1/1 Running 0 5m45s
kube-system netd-2889r 1/1 Running 0 5m45s--workload-metadata=GKE_METADATA の部分について、一部のノードプールでは従来型のクラスタメタデータを利用したい場合は、--workload-metadata=GCE_METADATA を明示的に指定することで特定のノードプール単位での挙動変更ができるようです( GKEMETADATAか GCE METADATAかの違い)。詳しくは、クラスタ メタデータの保護を参照。
既存ノードから有効化した場合の考慮点
ドキュメントには以下の記載があり、アプリケーションの設定を何らか変更しなければならないかのように読み取れます。結果としては、この言葉であまり思い当たる部分がないとき、あるいは小難しい使い方をしないないときには考慮不要かと思います。
Workload Identity を有効にしたら、アプリケーションを新しいノードプールに移行する前に、Workload Identity を使用して Google Cloud への認証を行うようにアプリケーションを構成する必要があります。
外部サービスを利用していてもシークレットキーを用いている場合は対処不要でした。
もし GKE ワーカーノード (Node Pools) そのものに対して付与したロールに依存しているアプリケーション動作がある場合は、影響を受けるのではないかと考えられます(未検証)。
仕様の補足説明
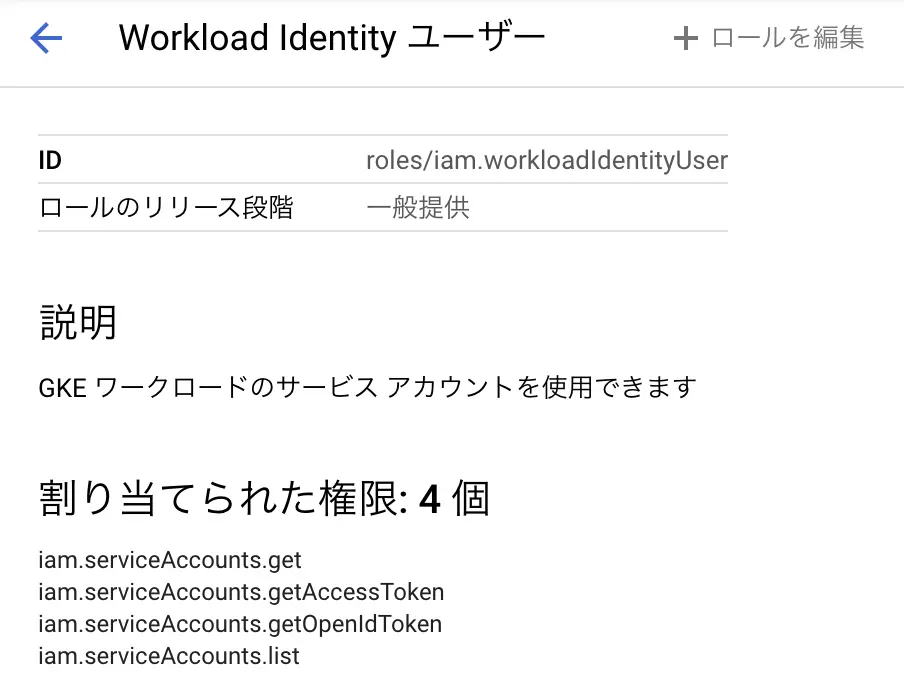
roles/iam.workloadIdentityUser ロール
GCP サービスアカウントと Kubernetes サービスアカウントを関連付けるコマンドは以下の通りです。
# 再掲コマンド
gcloud iam service-accounts add-iam-policy-binding $GSA_NAME@$GSA_PROJECT.iam.gserviceaccount.com \
--role roles/iam.workloadIdentityUser \
--member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]"ここで唐突に登場している --role roles/iam.workloadIdentityUser ロールは何なのでしょうか。答えはGCPのコンソールからも確認できますが、サービスアカウントのトークン取得などの参照系の権限を与えているようです。
ID の有効範囲
ドキュメントには IDの同一性 (Identity sameness) と表現されていますが、Google Service Account とのマッピングは Namespace/KubernetesServiceAccount の形式でマッピングされるため、GKEクラスタ単位のレベルでは区別しないようです。言い換えると、Kubernetes クラスタが物理的に複数のクラスタに分断されていても、GCPのプロジェクトとして同一空間にある場合は共有できるということ。
便利なケースが多いと思いますが、信頼できない他チームが管理する Kubernetes クラスタが共存している場合は都合が悪いことがあるかもしれませんので注意が必要です。
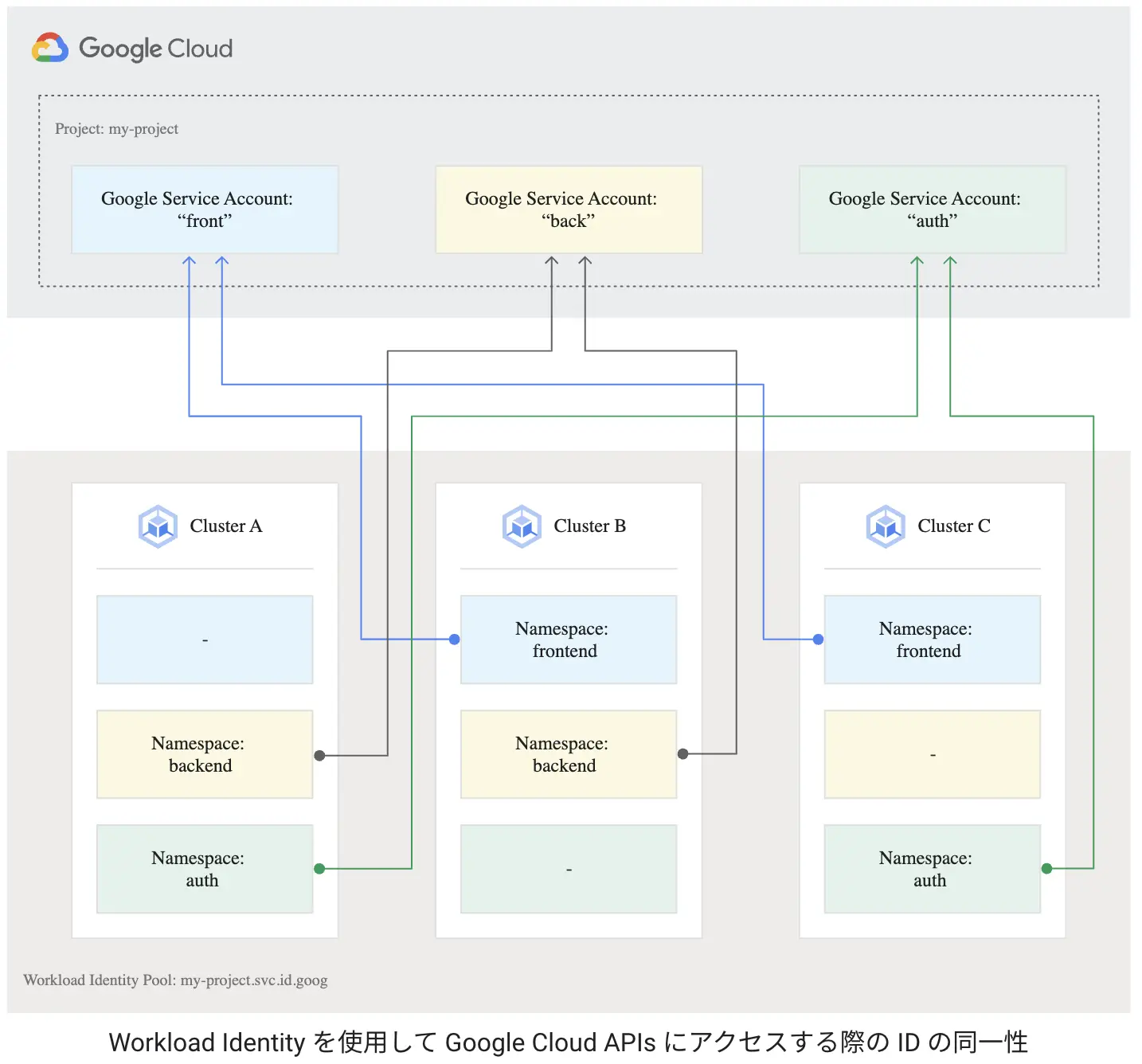
引用:Workload Identity | Google Kubernetes Engine(GKE) | Google Cloud
Workload Identity で別のプロジェクトから割り当てを使用する
GKE バージョン 1.24 以降を実行しているクラスタでは、Google Cloud API を呼び出すときに、必要に応じて別の Google Cloud プロジェクトの割り当てを使用するように Kubernetes サービス アカウントを構成できます。これにより、メイン プロジェクトでは割り当て全体を使用せず、クラスタ内のさまざまなサービスには他のプロジェクトからの割り当てを使用できます。
Workload Identity で別のプロジェクトから割り当てを使用する | Google Kubernetes Engine(GKE) | Google Cloud
Workload Identity あるいは大体方式の整理
| 手段 | 説明 | リスク | AWSにおける表現 |
|---|---|---|---|
| Workload Identity | [推奨] ubernetes リソースを使用して Google Cloud サービス アカウントを構成できます。この認証方法がユースケースに当てはまる場合は、最初の選択肢になります。 | 特筆事項なし(もっとも安全) | aws-auth によるサービスアカウントとIAMユーザーやロールのマッピング |
| ノードの Compute Engine のデフォルトのサービス アカウント | ノードプールの作成時にサービス アカウントを指定しなければ、GKE はプロジェクトに Compute Engine のデフォルトのサービス アカウントを使用する。デフォルトの Compute Engine サービス アカウントは、そのノードにデプロイされているすべてのワークロードで共有される。 | 必要のないアプリケーションにまで権限が過剰にプロビジョニングされる可能性がある | EC2に割り当てたロールの権限 |
| サービスアカウントキー | 秘匿情報(キー)を Secret として保存して利用する。アプリケーションにクレデンシャル情報を保存して利用することを意味する。 | サービス アカウント キーには有効期限がないため、安全に利用するためには手動でローテーションする必要がある。セキュリティ侵害を受けた場合、それが検出されなければ侵害の範囲が拡大する可能性がある。 | IAMのクレデンシャルキー |
まとめ
Workload Identity の特徴や使い方の概要を説明しました。
Kubernetes のサービスアカウントとクラウドプロバイダーの認証・権限機能との関連付けは面倒だと思っていましたが、AWS (EKS) に比べるとひと手間分くらいは理解しやすく扱いやすい印象でした(AWS EKS が劣っているという意味ではありません)。
キー情報を Secret や JSON などで管理するのは漏洩リスクのほか手間の問題もありますので、Workload Identity を積極的に使っていきたいですね。


![[GKE] Kubernetes を 1.18から1.22までアップグレードした記録](/tcard/91686cf2-ea26-4c42-b218-763560e70bda/2022-06-25-91686cf2-ea26-4c42-b218-763560e70bda.webp)

